The making-of Tic Tac Toe

How I began to code logic for my games, and ended up discovering something interesting...
I've been making games with some logic for decades. This time I decided to take a new direction, and instead of using my old methods, I wanted to try something in the field of standard artificial intelligence (AI) computing.
At first, I had to choose a game with very simple logic and decide which AI algorithm to use:
- Tic Tac Toe game is widely used to demonstrate AI algorithms. I guess everyone already knows Tic Tac Toe, so no more about that here.
- Minimax is a common AI for games, because it's easy to understand and use. Shortly put, Minimax is a decision-making algorithm to choose the next move for a player.
Minimax is a general-purpose algorithm, but it needs game specific adaptation for evaluating the best move. In Tic Tac Toe, that evaluation is to check for a line-of-three tokens, which is quite simple to do, but actually takes very much processing power, and in practice, it's not always possible (or necessary) to evaluate all moves, especially, if a game is anymore complicated than Tic Tac Toe.
Minimax processing time can be alleviated by "search-depth" to limit how many moves ahead are to be evaluated. In Tic Tac Toe, Minimax plays perfectly at search-depth 9 due to it can evaluate all possible moves in the future. But what happens if search-depth is limited?
I coded Tic Tac Toe with Minimax and let it play against a random-opponent with search-depths from 0 to 9. The table below shows Minimax (AI) and random-opponent winnings (P2) up to search-depth 6.

Initially AI is as bad as random player, but gets quickly better and better as search-depth keeps increasing until at search-depth 6 AI plays perfectly and loses no games anymore. Now, if we could see what AI "thinks" between random and perfect play, we can define all about Tic Tac Toe tactics.
A very interesting finding, indeed.
However, Minimax does not think like us and it's not readily clear why AI was winning. To understand that, we need to analyze games it plays to dig out logical patterns based on what we think and what are looking for.
The table shows that AI get's better already at search-depth 1, which is just the next one move so the first Tic Tac Toe tactic could be defined as "Win a line of three" (whenever possible). Our second tactic at search-depth 2 is then clearly (due to Tic Tac Toe is turn-based) to try to "Block a line of three". When search-depth increases we need to look farther ahead and it gets more challenging to find patterns, which is great, because I really like about this kind of challenges :)
Lets's analyze the games illustrated below:
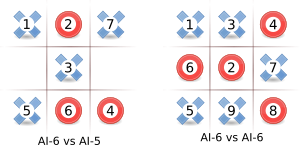
The picture shows how AI improves when increasing search-depth from 5 to 6. In the first game, O has search-depth 5 so it can peek only five moves ahead, which is not enough to avoid mistake it makes on the second move. In the second game, the both AIs have search-depth 6 so the game is tied, of course. A human player probably would play in the center cell intuitively, but when coding AI it's good to understand also why.
Once you have defined the tactics, the game logic is easy to code more effectively and avoid excessive computation that would slow it down unnecessarily. For example, Tic Tac Toe decision-making needs just these six tactics of how to win Tic Tac Toe.
What conclusion, if any, can be drawn from this experiment?
Well at least it was fun, which is as important as any other aspect - especially in the gaming world. It's also worth thinking about: Could you offload some boring work to AI when making your next game.
Leave a comment
Log in with itch.io to leave a comment.